5분 만에 알아보는 파이썬 웹 스크래핑
March 29, 2020
구슬이 서 말이어도 꿰어야 보배다.
요즘엔 데이터가 재산이라는 말이 있습니다. 그럼 세상에서 가장 많은 데이터는 누가 가지고 있을까요? 세상에서 가장 많은 데이터는 웹상에 공개된 형태로 존재하고 있습니다. 하지만 이 데이터를 가지고 있는다고 해서 바로 부자가 되지는 않습니다. 구글이 데이터를 잘 정리해서 검색하기 쉽게 만들어 준 것처럼 데이터를 잘 꿰어야지만 비로소 보배가 되는 것이지요.
웹 상의 데이터를 꿰는 과정인 웹 스크래핑의 세계에 처음으로 발을 들이고 싶으신 분들을 위해 간략한 가이드를 작성해 보았습니다.
웹 크롤링? 웹 스크래핑?
먼저 용어 정리를 하고 가겠습니다. 웹 크롤링과 스크래핑은 저를 포함해서 많은 분들이 용어를 섞어서 사용하고 있는데, 제가 이해하고 있는 정의는 다음과 같습니다.
웹 크롤링 : 웹을 여기저기 돌아다니는 행위
웹 스크래핑 : 웹 원하는 자료를 추출 해내는 행위
웹에서 원하는 데이터를 모으려면 보통 웹을 돌아다니는 행위와 각 페이지에서 원하는 자료를 추출 해 내는 행위가 함께 이루어지므로, 두 용어는 구분해서 쓰지 않습니다. 하지만 이번 포스트에서는 하나의 페이지에서 자료를 추출 해 내는 것에 대해서만 다룰 예정이므로 웹 스크래핑이라는 용어를 사용하겠습니다.
실습을 위해 필요한 환경
이번 포스트에서는 파이썬을 이용한 웹 스크래핑을 해 볼 예정입니다. 이번 포스트에서 나오는 예제를 실행시켜보기 위해서 필요한 환경은 다음과 같습니다.
python3
bs4 # pip install bs4
requests # pip install requests웹 스크래핑
먼저 우리가 웹브라우저를 이용해 페이지에 접근을 하는 과정을 간단하게 표현하면 다음과 같습니다.
1. 웹브라우저에서 서버에 페이지를 요청 (request)
2. 서버에서 웹브라우저에 페이지를 보내줌 (response)
3. 웹 브라우저에서 페이지를 이쁘게 보여줌 (render)웹 스크래핑 하는 과정도 우리가 웹브라우저를 사용하는 과정과 크게 다르지 않습니다.
1. 파이썬에서 서버에 페이지를 요청 (request)
2. 서버에서 파이썬에 페이지를 보내줌 (response)
3. 페이지에서 원하는 데이터를 추출 (parsing)웹브라우징과 웹스크래핑은 페이지를 요청하고 받는 1번, 2번 과정은 동일하고, 3번과정에서 페이지를 보여주느냐, 페이지에서 데이터를 추출하느냐만 다르다고 생각하시면 됩니다.
위의 예제는 가장 단순한 상황에서의 웹브라우징, 스크래핑을 설명 한 것이고, 만약에 로그인같은 좀 더 복잡한 과정을 거쳐서 페이지를 요청해야 하거나, 서버에서 보내준 페이지를 단순히 보여주는 형태가 아닌, 동적으로 브라우저에서 페이지를 만드는 형태라면 웹스크래핑 과정도 그에 맞게 바뀌어야 합니다. 이런 경우에는 selenium 이라는 패키지를 이용해서 대응 할 수 있습니다.
예제: 네이버 뉴스 헤드라인 가져오기
이제부터 네이버 헤드라인 뉴스의 제목을 가지고 오는 예제를 살펴보겠습니다. 먼저 파이썬에서 웹페이지 요청을 하고, 그 다음에는 웹페이지를 파싱해서 원하는 정보를 추출 해 내는 순서로 설명드리겠습니다.
1. 파이썬에서 웹페이지 요청하고 받기
# 웹페이지 요청을 위한 패키지
import requests
# 네이버 뉴스 페이지 url
url = 'https://news.naver.com/'
# 네이버 뉴스 페이지 요청, 응답 저장
response = requests.get(url)
print(response) # 응답 형식은 <Response [200]>
print(response.status_code) # 응답 코드는 200 (정상 응답)
print(response.text) # 응답 내용 출력 (html, 엄청 긺)코드는 엄청 간단합니다. 원하는 url을 requests.get 함수의 인자로 넣어주고, 함수를 호출하면 서버에 웹페이지를 요청하고, 응답결과를 반환합니다. 응답결과는 Response 객체로 되어 있는데, 자세한 사항은 Requests 문서를 보시면 도움이 됩니다.
현재 Response 객체에서 우리가 필요한 내용은 두 가지입니다. response.status_code를 확인해서 서버로부터 정상 응답(200)이 왔는지, 정상응답이 왔다면 response.text로부터 해당 페이지의 내용을 가져오는 것입니다.
response.text의 내용을 보면, 긴 text 형식의 html 파일입니다. 여기에서 우리가 원하는 헤드라인 뉴스의 제목을 추출 해 내기 위해서는 html을 파싱하는 작업이 필요합니다.
2. 웹페이지에서 원하는 데이터 추출하기
# 웹페이지 파싱을 위한 패키지
from bs4 import BeautifulSoup
# response로 부터 html 가져오기
html = response.text
# BeautifulSoup 으로 html 파싱
soup = BeautifulSoup(html, 'html.parser')
# CSS Selector 로 헤드라인 뉴스가 있는 항목 선택
hdline_titles = soup.select('#today_main_news > div.hdline_news > ul > li > div.hdline_article_tit > a')
# 헤드라인 뉴스가 있는 a 태그에서 텍스트만 추출
for title in hdline_titles:
print(title.get_text(strip=True)) # 결과 출력BeautifulSoup은 html을 파싱해주는, 말 그대로 아름다운 패키지 입니다.
html을 파싱 한 후 가장 중요한 것은 우리가 원하는 정보가 있는 곳을 찾는 작업입니다. 개인적으로는 이 작업이 웹 스크래핑에서 가장 시간이 오래 걸리는 부분으로 생각됩니다.
html에서 원하는 정보가 있는 곳을 선택하는 방법으로는 CSS Selector, XPath 등이 있는데, 여기서는 CSS Selector를 이용했습니다. 두 작업 모두 CSS에서 원하는 정보가 있는 곳의 태그, 클래스 이름, 아이디를 찾아내는 작업이 필요합니다. 크롬 개발자도구를 이용하면 보다 편리하게 CSS Selector를 찾아 낼 수 있습니다.
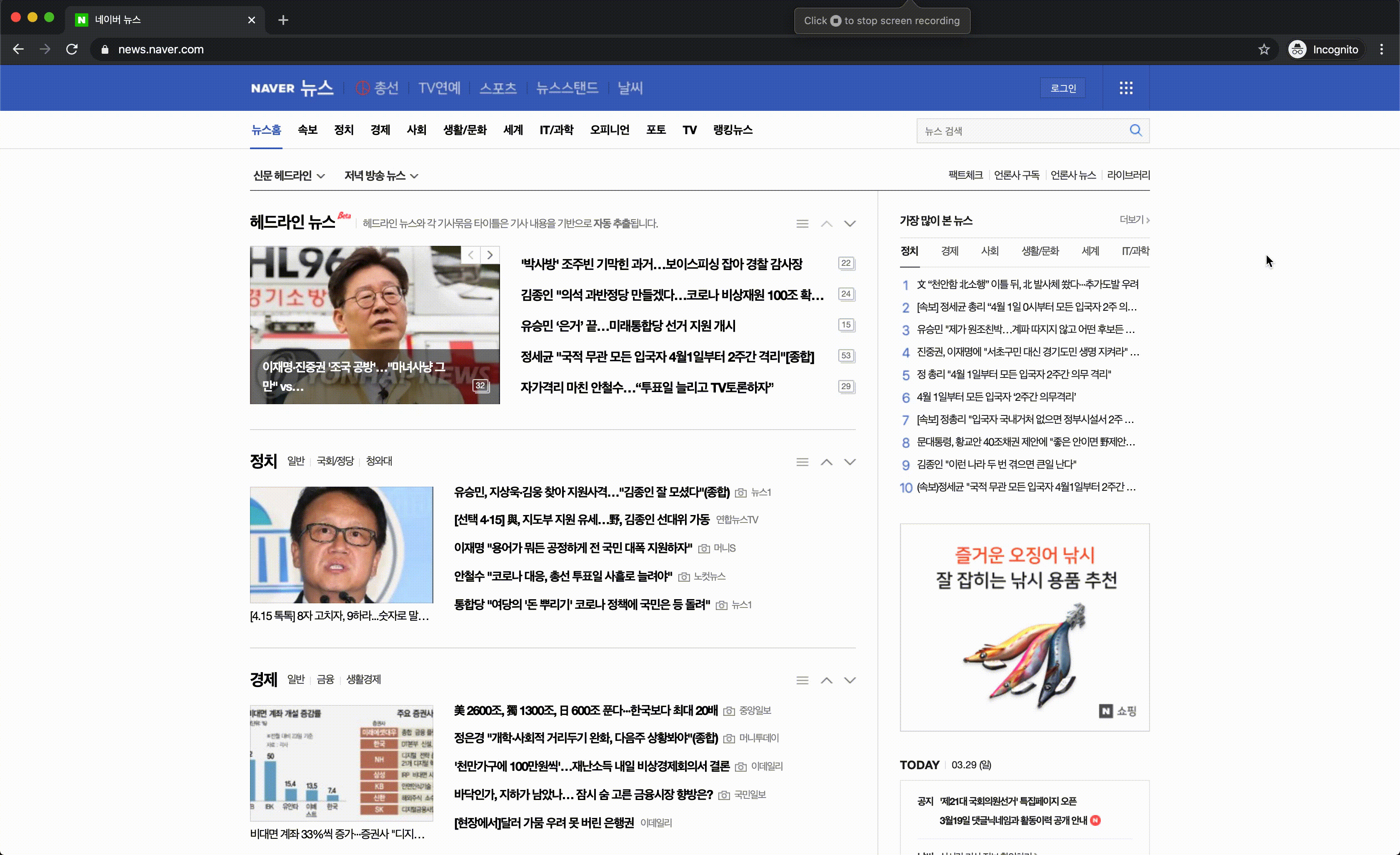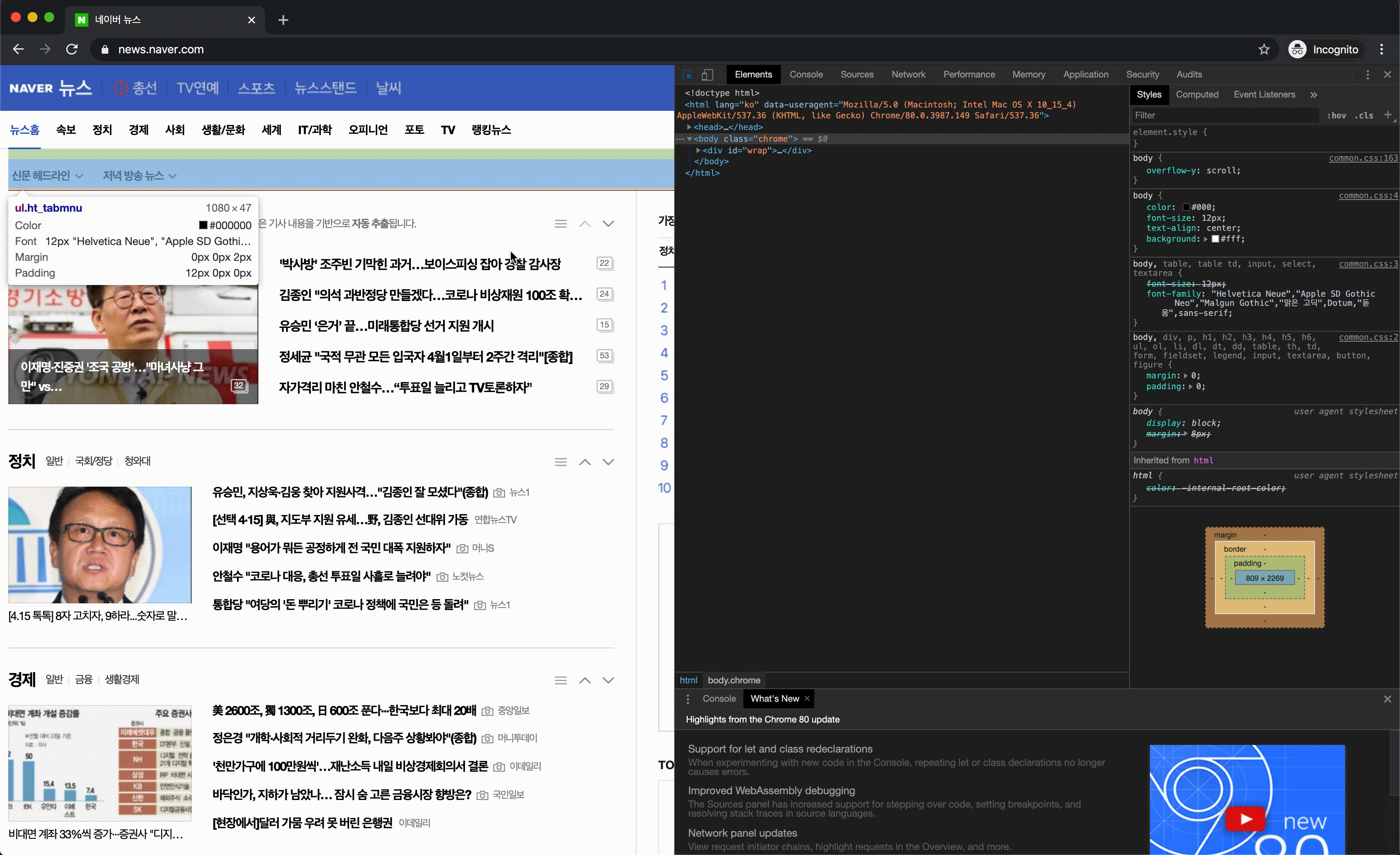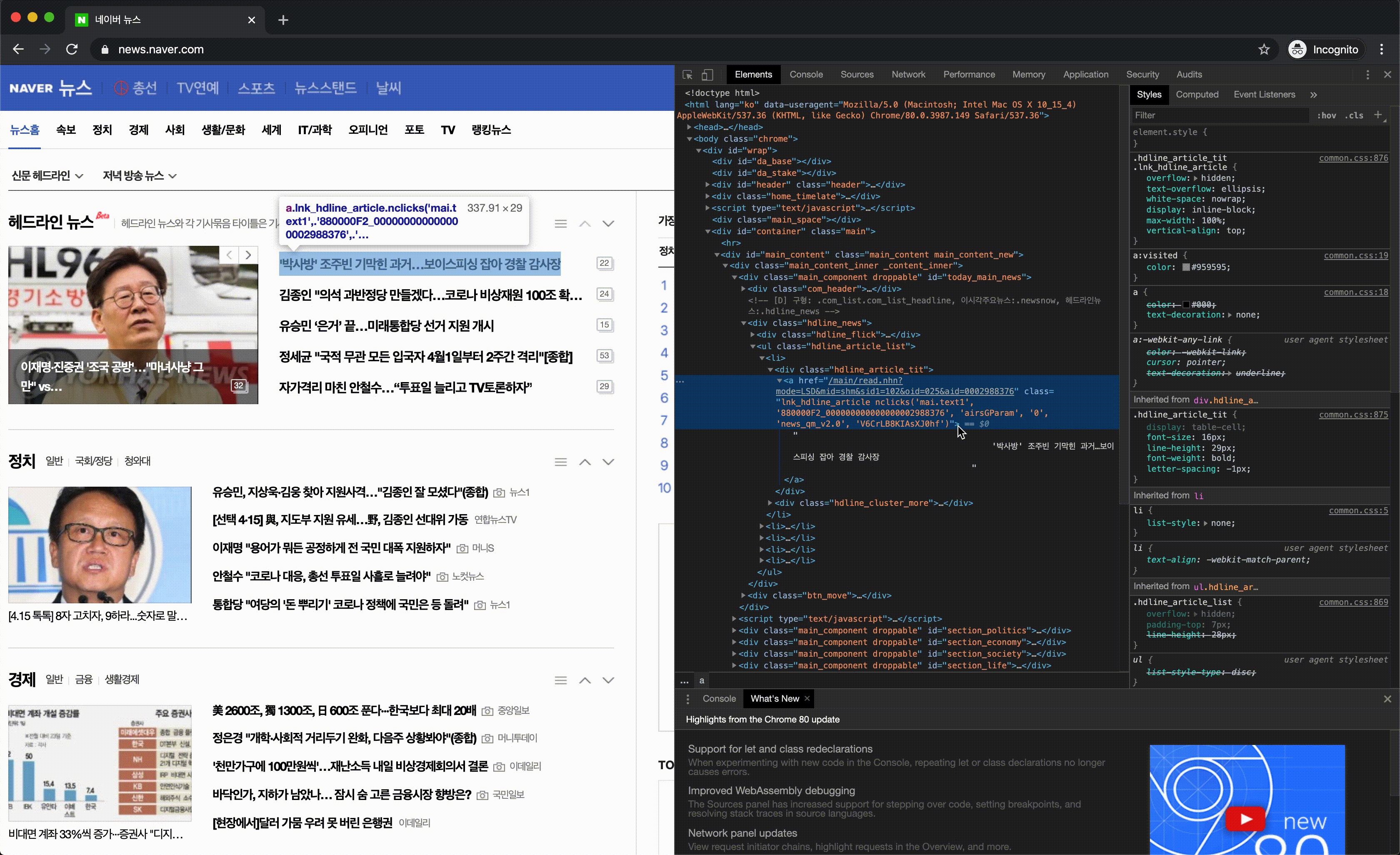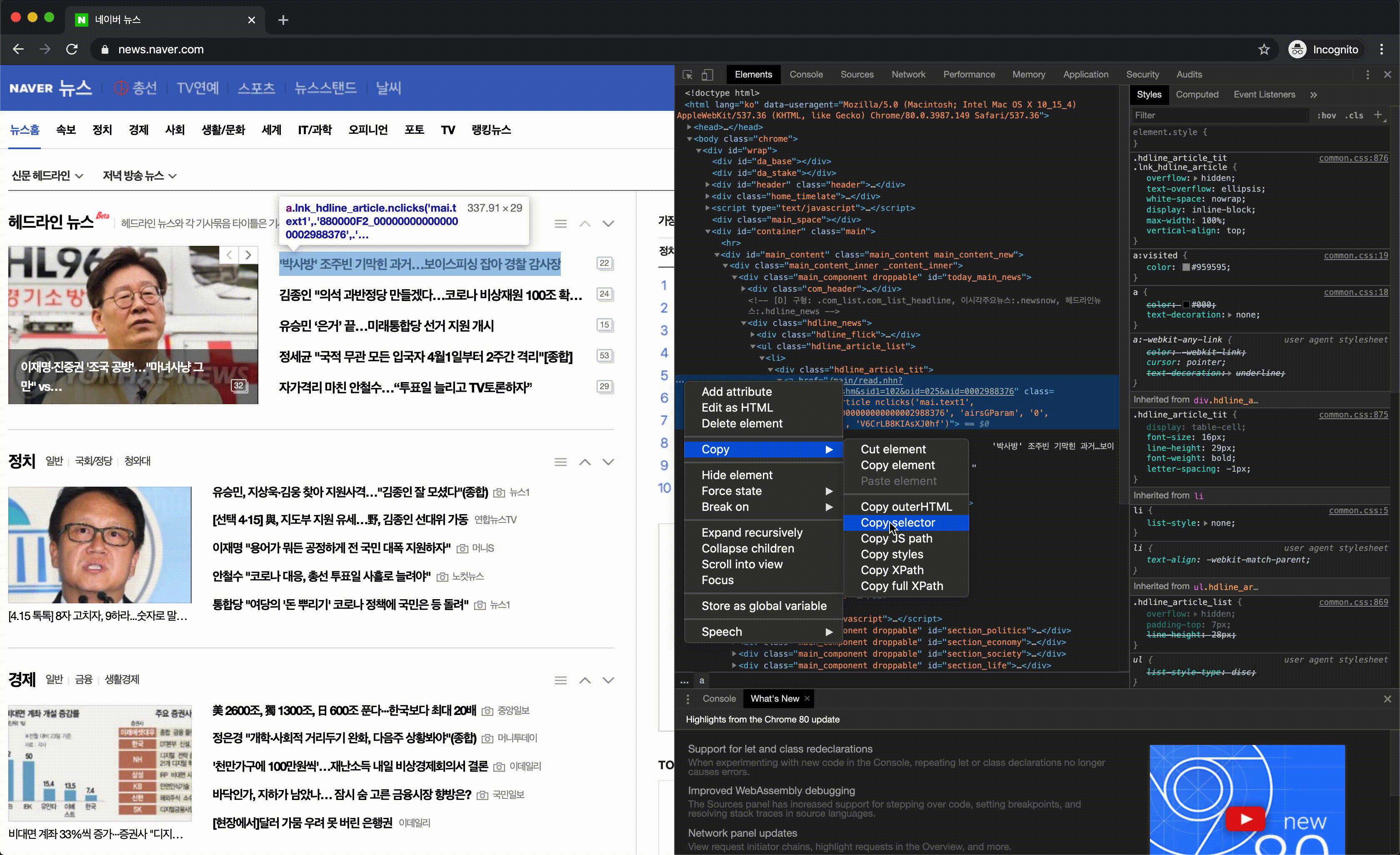
크롬 개발자도구를 이용해 찾아낸 CSS Selector는 아래와 같습니다.
#today_main_news > div.hdline_news > ul > li:nth-child(1) > div.hdline_article_tit > a이 셀렉터는 하나의 제목을 가져오는 것이므로, 제목을 모두 가져오기 위해서는 li 태그의 모든 항목을 가져오는 것이 필요합니다. 따라서 이 글에서는 CSS Selector를 아래와 같이 변경 한 후, 코드에 적용하였습니다.
#today_main_news > div.hdline_news > ul > li > div.hdline_article_tit > a보다 자세한 CSS Selector 문법은 다음에 다루도록 하겠습니다.
마지막으로
이 글에서는 웹페이지로부터 원하는 정보를 추출 해내는 스크래핑의 간단한 예제를 살펴보았습니다. 여기서 원하는 url을 순차적으로 탐색하는 크롤링 기능만 넣으면 쓸만한 웹 크롤러를 만들 수 있습니다. 웹 크롤링에서 가장 중요한 것은 대상이 되는 서버에 많은 부담을 주지 않는 것과, 해당 웹사이트에서 크롤링을 원하지 않는 자료는 크롤링 하지 않는 것입니다. 서버에 부담을 주지 않는 것은 크롤러에 일정 딜레이를 주어서 해결 할 수 있고, 해당 웹사이트에서 크롤링에 대해 어떤 정책을 가지고 있는지는 웹사이트의 robot.txt를 참고하면 알 수 있습니다.
웹 크롤링을 보다 쉽게 만들어주는 Scrapy 프레임워크 사용 방법에 대해서도 추후에 다루도록 하겠습니다.